
Чем больше - тем лучше? Определяем полноту и источники ядра
Некоторые SEO-специалисты и директологи меряются размером семантического ядра. Но действительно ли чем больше, тем лучше? Я видел, как собирают тысячи запросов, а потом волокут за собой ядро, как чемодан без ручки – бросить жаль (я так долго его собирал!), а внедрить такой объем запросов не получается. Так определяется ли качество семантического ядра объемом запросов? И нужно ли использовать все возможные источники для составления сем. ядра? Я убежден, что специалисты спутали запрос и потребность. Важно охватывать все потребности, но это не значит, что нужно собрать как можно больше запросов. В этой статье объясню, в чем разница между потребностью и запросом, и как определить, какие источники для составления семантического ядра использовать.
Больше не равно лучше!
Почему? Запрос — частный случай потребности, скрытой за конкретной формулировкой. Запрос не равен потребности! Потребность – это единица спроса.
Например:
Вводится «ноутбуки apple цена» или «эпл ноут», а подразумевается «купить ноутбук apple macbook» и Яндекс понимает, что за запросами стоит одна и та же потребность. Это видно по ТОП-10, выдача по этим запросам очень похожа. Нужно охватывать больше потребностей целевой аудитории, а сколько запросов будет в потребности – дело второе.
Какие источники семантики использовать?
Мы собрали все возможные источники и отобразили их на схеме:

Только в этой «рыбе» больше 30 источников, но для конкретного проекта нет смысла использовать все. Какие источники нужно задействовать зависит от тематики проекта, от его возраста, от задачи, для которой нужна архитектура сайта. Большое количество запросов без понимания потребности, которая за ними стоит, бесполезно.
Варианты стратегий расширения семантики
Типовые задачи и стратегии, которые помогут определить, с чего начать расширение семантического ядра.
- Для старого сайта для сбора полного ядра хорошо в источники добавить счетчики Яндекс.Метрика, Гугл.Аналитикс, Ливинтернет и т.д.
- Для нового сайта хорошо спарсить семантику и архитектуру конкурентов и организовать свою.
- Для портала с большим охватом тематик тоже подойдет парсинг H1 конкурентов, SpyWords, Prodvigator, SemRush.
- Если сайт узкотематический информационный проект, то лучше парсить базы типа MOAB вглубь по стему ключа, например, *керамогранит*, *плитк* … и составлять архитектуру под тематические статьи с полным ответом на потребность (тут нужна крутая экспертность).
- Если стоит задача нарастить трафик магазину, стоит собрать в первую очередь все счетчики и расширить по максимуму через подсказки, Вордстат и какую-нибудь базу (например, MOAB работает достаточно быстро по сравнению с другими базами, но платный).
- Для большого информационного проекта также можно собрать семантику конкурентов по выдаче через сервисы типа SpyWords и Продвигатор, кластеризовать её и раскидать по основным разделам, отсортировав кластеры по убыванию суммарной частоты. Все это закладывается в контент-план на год и системно закрывается собственными тематическими статьями, начиная с самых популярных тем.
Сбор семантики для больших порталов
Отдельно опишу сбор семантики для больших порталов. Если портал большой и ищет направление, куда расти по трафику, то действуем так:
- Выгребаем всю семантику по нише (обычно 1-3 миллиона фраз);
- Кластеризуем;
- Убираем ~30% информации, но не по каждому запросу, а кластерами (есть методики);
- Полученное раскидываем на пару десятков разделов.
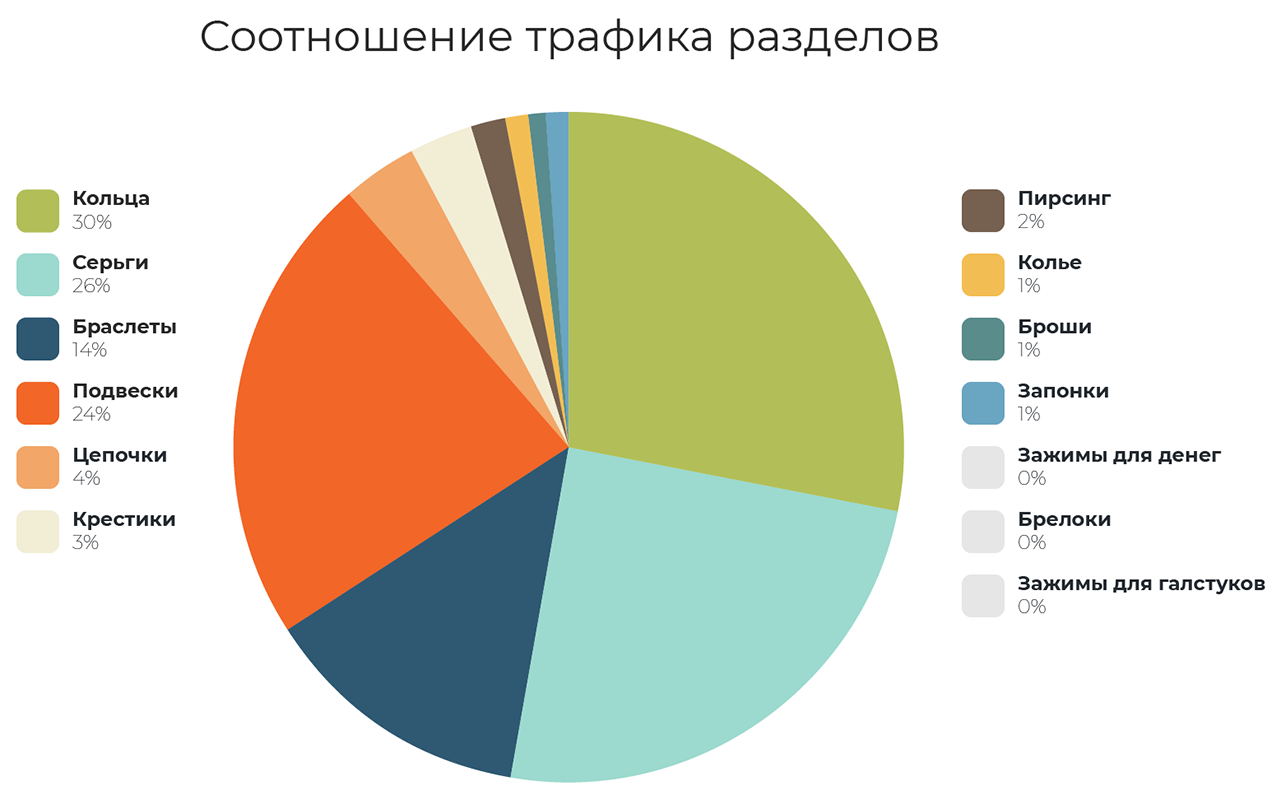

Мы видим, что спрос распределен неравномерно, 90% трафика находится в 4 разделах из 14. Следовательно, усилия по привлечению трафика лучше направить туда.
Резюме
Пользуйтесь разными источниками, чтобы сделать полное ядро. Но полнота определяется не количеством запросов, а тем, все ли потребности аудитории вы охватили.



Здравствуйте, Дмитрий! Спасибо Вам за полезную статью! Материал изложен понятно и доступно, четко и по делу.
Дмитрий, позвольте попросить у Вас совет.
Планирую создать нишевой блог по теме «Тайм-менеджмент для научных работников».
Какие поисковые запросы мне следует выбрать для семантического ядра: запросы, связанные с тайм-менеджментом, или же запросы, связанные с научными работниками и научной деятельностью? Или возможен какой-то третий вариант?
Казалось бы, логичен первый вариант (запросы по тайм-менеджменту), но… Боюсь, что в этом случае на блог станут заходить многие из тех, кто не имеет никакого отношения к научной работе. Уровень отказов будет расти, поведенческие показатели – падать…
Дмитрий, посоветуйте, пожалуйста, как грамотно собрать СЯ, чтобы избежать этих проблем?
Заранее благодарен Вам за ответ!
Приветствую, Игорь.
Если вы делаете узкотематический блог лучше забирайте все запросы и общие по тайм-менеджменту и запросы связанные с задачами ученого. Семантика это спрос, поэтому спрос на эксклюзивные запросы может быть очень низкий и не постоянный.
Самый простой способ искать популярные статьи по сервисам видимости и там смотреть видимость топовых материалов и сайтов. Опыт подсказывает что в узкой теме каких-то очень необычных запросов с частотой больше 10 на запрос и 100 на кластер может не оказаться совсем.
Как собирать семантику лучше смотрите базовый курс по СЯ на ютубе, вот ссылка https://www.youtube.com/playlist?list=PLwFlVp7NVdrBSUTaTeYocreAtHfoRT2Sc